In my program each major unit ends with a few projects. There are a couple of projects that just feel like really long labs, and then there is a final project that is a bit more open-ended (AKA fun). After you’ve finished your project, you’re required to film a video walkthrough, write a blog post about the experience, and lastly you have an assessment with a Flatiron instructor.
For the object-oriented Ruby section, they asked us to create a CLI gem that scraped data from a webpage or via an API. Despite having a little experience with web scraping and APIs in Python, it still took me a while to get my head around the best way to approach the project.
Specific Project Requirements:
- * Package as a Ruby gem
- * Provide a CLI on gem installation.
- * CLI must provide data from an external source, whether scraped or via a public API.
- * Data provided must go at least a level deep, generally by showing the user a list of available data and then being able to drill into a specific item.
My Gem Overview / Walkthrough
I built a gem that connects to the NPR API. Through the command line you can pick an NPR radio program and see its recent stories, then drill into those stories to see further information. You can also choose to read the whole story through the browser.
The interface looks like this:
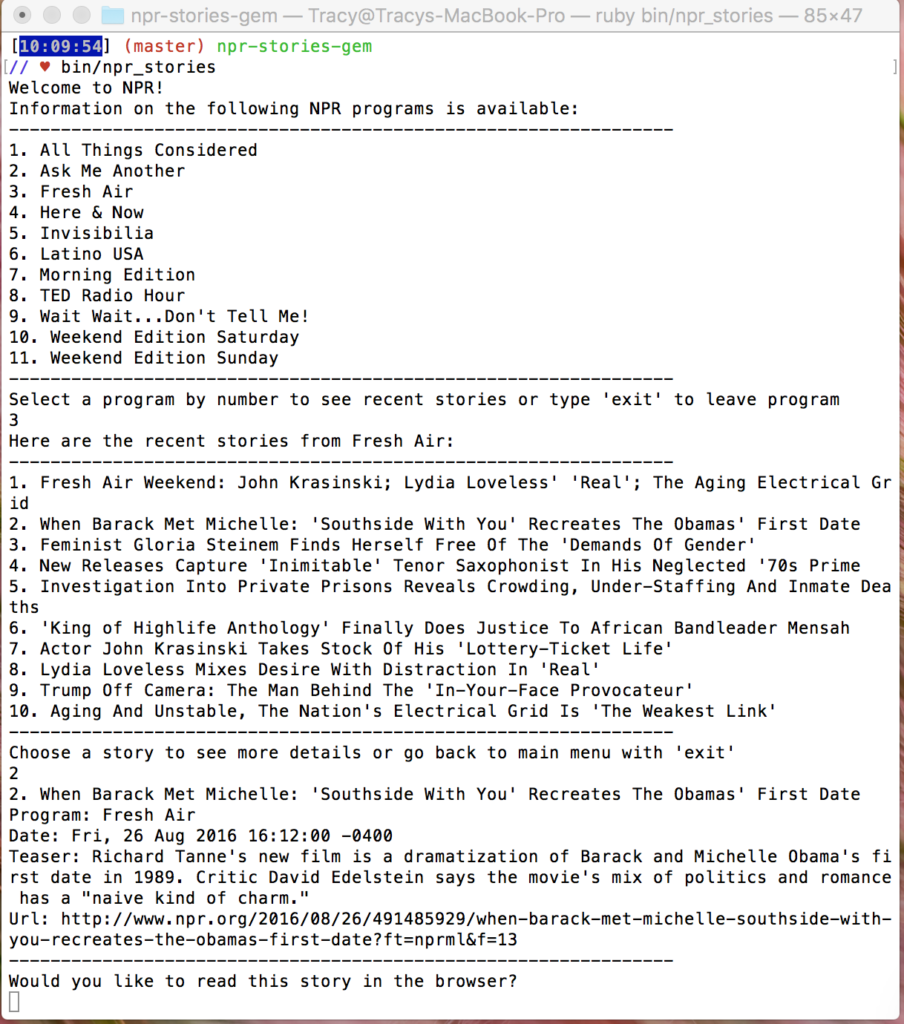
Here is the video walkthrough of my gem:
Choosing a project and data source:
I knew from the beginning that I wanted to work with the NPR API. It’s been out for years and I’ve never messed with it. So I headed over to the documentation. I knew that I wanted to be able to read recent news stories, but I wasn’t sure if I should filter by program(radio show), story topic, feature, or date. There was a handy query generator that was useful for quickly determining what my options and results looked like. Eventually I chose program, since that’s the option that I would want in real life. Another plus of this was that there were a manageable number of programs available. There were more than 30? 40? topics, and that would have just been a mess and a terrible user experience.
While I was checking out the API I remembered that there was an NPR API course on Codecademy in Python. I ran through the first couple of lessons to get a feel for what the API returned, then returned back to my project. You can get sucked into those Codecademy projects!
The default result format is NPRML, a custom XML for representing NPR’s digital content. Other format options included JSON, HTML, Atom, and RSS. I’d worked with JSON back when I was playing around with Python/Beautiful Soup, so I wanted to try my hand at XML.
Here is what an NPRML doc looks like:

Pretty straightforward, right? In order to get a key just for personal use I needed to register for an NPR account. It wasn’t like a special developer’s account or anything, just a regular NPR commenter account. Props to NPR for also allowing you to sign in via other social logins such as Twitter and Facebook.
Issues or rather, Pitfalls:
- * Objects, objects, objects – I started out thinking that I would have a Story object and also a Scraper object. Through the course of building this out, I also added in a CLI class and a Program class. With all of these different objects, at times I became a bit unsure of where I should assign certain methods, or responsibilities. Like, in order to display a story’s content, who should be in charge of that? The story? The CLI? In the end I just had to make a choice and move on.
- * I hard coded everything in the beginning, just to get things moving. For example, I explicitly limited the number of stories returned in the API query so I would have a dependable number of stories to work with every time. Also all of the Program search id keys were explicitly laid out as class constants: like FRESH_AIR = 2, ALL_THINGS_CONSIDERED = 18, etc. This unfortunately lead to my CLI menu being super long, because I used a case statement to account for every entry. Once I created a Program class, I had the API id key as an attribute of the Program, and things became much tidier and more importantly, the code was more readable.
- * I made a few embarrassing mistakes when trying to access Programs and Stories in my CLI menu. Just the usual adding or subtracting 1 to a number when dealing with array indexes.
Thoughts
- * I’m honestly surprised that it took me so long to finally put this project to bed. I’ve been working on this project on and off for about two months. When I first came to the project in the curriculum, I was intimidated, so I skipped it, saying that I would come back. Honestly, I think that I did need that time to let OO marinate in my brain, but when I felt ready to come back to the project, I had totally forgotten where I was in the project!!! A couple of times I just started over from scratch. This has happened to me with my knitting projects too :(. Taking better status notes will help me in the future if I’m going to take a break from a project, coding or otherwise.
- * Another thing that I realized is that I also should have started smaller in my ambitions for the project, and added on top of code once it was working. It would have made troubleshooting easier. Similar to my Sinatra project, I initially tracked quite a few story variables, and ended up discarding them by the end of the project.
- * At first I was testing my assumptions via IRB, but eventually I went with Pry. I’m not a total convert, but Pry definitely is a useful gem!
- * Readability is key, and every little bit counts, whether it’s naming objects or using different commands that do the same thing – .search vs .css for example.
- * JSON > XML
- * There are some other steps I’ll need to take to make this gem RubyGems ready, but for now I’m just happy that it works! 🙂 Back to working on Rails!